 Minotauromaquia
Minotauromaquia
I statistikker, den mode af et sæt tal er nummer der vises oftest i sættet. Et datasæt behøver ikke nødvendigvis kun at have én tilstand - hvis to eller flere værdier er "bundet" for at være den mest almindelige, kan sættet siges at være bimodal eller multimodal, henholdsvis - med andre ord er alle de mest almindelige værdier setets tilstande. For detaljeret kig på processen med at bestemme et datasætets tilstand (er), se Trin 1 nedenfor for at komme i gang.
Metode En af To:
Finde tilstanden til et datasæt
-
 1 Skriv tallene i dit datasæt. Modes er typisk taget fra sæt af statistiske datapunkter eller lister over numeriske værdier. For at finde en tilstand skal du derfor finde et datasæt for at finde det. Det er svært at lave modeberegninger mentalt for alle, men det mindste datasæt, så i de fleste tilfælde er det klogt at begynde at skrive (eller skrive) dine data. Hvis du arbejder med papir og blyant, er det bare at skrive værdierne af dit datasæt i rækkefølge, mens du, hvis du bruger en computer, kan bruge et regnearksprogram til at strømline processen.
1 Skriv tallene i dit datasæt. Modes er typisk taget fra sæt af statistiske datapunkter eller lister over numeriske værdier. For at finde en tilstand skal du derfor finde et datasæt for at finde det. Det er svært at lave modeberegninger mentalt for alle, men det mindste datasæt, så i de fleste tilfælde er det klogt at begynde at skrive (eller skrive) dine data. Hvis du arbejder med papir og blyant, er det bare at skrive værdierne af dit datasæt i rækkefølge, mens du, hvis du bruger en computer, kan bruge et regnearksprogram til at strømline processen. - Processen med at finde et datasæt er mode er lettere at forstå ved at følge med et eksempel problem. I dette afsnit skal vi bruge dette sæt værdier med henblik på vores eksempel: 18, 21, 11, 21, 15, 19, 17, 21, 17. I de næste trin finder vi tilstanden på dette sæt.
-
 2 Bestil tallene fra mindste til største. Derefter er det ofte en klog ide at sortere værdierne i dit datasæt, så de er i stigende rækkefølge. Selv om dette ikke er strengt nødvendigt, gør det processen at finde tilstanden lettere, fordi den grupperer ens værdier ved siden af hinanden. For store datasæt kan det være praktisk taget en nødvendighed, idet man sorterer gennem lange lister over værdier og holder mentale tal om hvor mange gange hvert nummer vises i listen, er svært og kan føre til fejl.
2 Bestil tallene fra mindste til største. Derefter er det ofte en klog ide at sortere værdierne i dit datasæt, så de er i stigende rækkefølge. Selv om dette ikke er strengt nødvendigt, gør det processen at finde tilstanden lettere, fordi den grupperer ens værdier ved siden af hinanden. For store datasæt kan det være praktisk taget en nødvendighed, idet man sorterer gennem lange lister over værdier og holder mentale tal om hvor mange gange hvert nummer vises i listen, er svært og kan føre til fejl. - Hvis du arbejder med papir og blyant, kan genskrivning spare tid på lang sigt. Scan sættet af tal for det laveste antal, og når du finder det, krydse det i det første datasæt og skriv det igen i dit nye datasæt. Gentag for det næstbedste nummer, tredje lavest osv., Og sørg for at skrive hvert nummer så mange gange som det forekommer i det oprindelige datasæt.
- Med en computer er dine muligheder mere omfattende - for eksempel vil de fleste regnearksprogrammer have mulighed for at omordne lister over værdier fra mindst til største med blot et par klik.
- I vores eksempel, efter ombestilling, skal den nye liste over værdier læses: 11, 15, 17, 17, 18, 19, 21, 21, 21.
-
 3 Tæl antallet af gange hvert nummer gentages. Herefter tælle antal gange, som hvert nummer i sættet vises. Se efter den værdi, der forekommer mest i datasættet. For relativt små datasæt med punkter arrangeret i stigende rækkefølge er det normalt et simpelt spørgsmål om at finde den største "klynge" af identiske værdier og tælle antallet af forekomster.
3 Tæl antallet af gange hvert nummer gentages. Herefter tælle antal gange, som hvert nummer i sættet vises. Se efter den værdi, der forekommer mest i datasættet. For relativt små datasæt med punkter arrangeret i stigende rækkefølge er det normalt et simpelt spørgsmål om at finde den største "klynge" af identiske værdier og tælle antallet af forekomster. - Hvis du arbejder med en blyant og et papir for at holde styr på dine tællinger, skal du prøve at skrive det antal gange, hver værdi indtræffer over hver klynge af identiske tal. Hvis du bruger et regnearksprogram på en computer, kan du gøre det samme ved at skrive dine totals i tilstødende celler eller alternativt ved at bruge et af programmets muligheder for at telle datapunkter.
- I vores eksempel (11, 15, 17, 17, 18, 19, 21, 21, 21) forekommer 11 en gang, 15 forekommer en gang, 17 forekommer to gange, 18 forekommer en gang, 19 forekommer en gang, og 21 opstår tre gange. 21 er den mest almindelige værdi i dette datasæt.
-
 4 Identificer den værdi (eller værdier), der forekommer oftest. Når du ved, hvor mange gange hver værdi opstår i dit datasæt, skal du finde den værdi, der forekommer det største antal gange. Dette er dit datasætets tilstand. Noter det der kan være mere end en tilstand i et datasæt. Hvis de to værdier er bundet til at være de mest almindelige værdier i sættet, kan datasættet siges at være bimodal, mens der er bundet tre værdier, er sættet trimodalt, og så videre.
4 Identificer den værdi (eller værdier), der forekommer oftest. Når du ved, hvor mange gange hver værdi opstår i dit datasæt, skal du finde den værdi, der forekommer det største antal gange. Dette er dit datasætets tilstand. Noter det der kan være mere end en tilstand i et datasæt. Hvis de to værdier er bundet til at være de mest almindelige værdier i sættet, kan datasættet siges at være bimodal, mens der er bundet tre værdier, er sættet trimodalt, og så videre. - I vores eksempel sæt, (11, 15, 17, 17, 18, 19, 21, 21, 21), fordi 21 forekommer flere gange end nogen anden værdi, 21 er tilstanden.
- Hvis en værdi udover 21 havde også opstod tre gange (som f.eks. hvis der var endnu 17 i datasættet), 21 og dette andet tal ville begge være tilstanden.
-
 5 Forveksl ikke datasættets tilstand med dets middel eller median. Tre statistiske begreber, der ofte diskuteres sammen, er midler, medianer og tilstande. Fordi disse begreber alle har lignende lydende navne, og fordi for en enkelt datasæt, kan en enkelt værdi undertiden være mere end en af disse ting er det let at forvirre dem. Men uanset om datasættets tilstand er også det er median eller middel, er det vigtigt at forstå, at disse tre begreber er helt uafhængige af hinanden. Se nedenunder:
5 Forveksl ikke datasættets tilstand med dets middel eller median. Tre statistiske begreber, der ofte diskuteres sammen, er midler, medianer og tilstande. Fordi disse begreber alle har lignende lydende navne, og fordi for en enkelt datasæt, kan en enkelt værdi undertiden være mere end en af disse ting er det let at forvirre dem. Men uanset om datasættets tilstand er også det er median eller middel, er det vigtigt at forstå, at disse tre begreber er helt uafhængige af hinanden. Se nedenunder: - Et datasæt er betyde er det gennemsnitlige. For at finde den gennemsnitlige, tilføj alle værdierne i datasættet, divider derefter med antallet af værdier i sættet. For eksempel for vores eksempel datasæt (11, 15, 17, 17, 18, 19, 21, 21, 21) ville gennemsnittet være 11 + 15 + 17 + 17 + 18 + 19 + 21 + 21 + 21 = 160/9 = 17.78. Bemærk at vi delte summen af værdierne med 9, fordi der er i alt 9 værdier i datasættet.

- Et datasæt er median er "mellemnummeret", der adskiller de nedre og højere værdier af et datasæt i to lige halvdele. For eksempel i vores eksempeldatasæt, (11, 15, 17, 17, 18, 19, 21, 21, 21) 18 er medianen fordi den er det midterste tal - der er præcis fire tal højere end det og fire tal lavere end det.Bemærk, at hvis der er et lige antal værdier i datasættet, er der ingen enkeltmedian. I disse tilfælde er medianen normalt taget til at være middelværdien af de to midterstal.

- Et datasæt er betyde er det gennemsnitlige. For at finde den gennemsnitlige, tilføj alle værdierne i datasættet, divider derefter med antallet af værdier i sættet. For eksempel for vores eksempel datasæt (11, 15, 17, 17, 18, 19, 21, 21, 21) ville gennemsnittet være 11 + 15 + 17 + 17 + 18 + 19 + 21 + 21 + 21 = 160/9 = 17.78. Bemærk at vi delte summen af værdierne med 9, fordi der er i alt 9 værdier i datasættet.
 1 Skriv tallene i dit datasæt. Modes er typisk taget fra sæt af statistiske datapunkter eller lister over numeriske værdier. For at finde en tilstand skal du derfor finde et datasæt for at finde det. Det er svært at lave modeberegninger mentalt for alle, men det mindste datasæt, så i de fleste tilfælde er det klogt at begynde at skrive (eller skrive) dine data. Hvis du arbejder med papir og blyant, er det bare at skrive værdierne af dit datasæt i rækkefølge, mens du, hvis du bruger en computer, kan bruge et regnearksprogram til at strømline processen.
1 Skriv tallene i dit datasæt. Modes er typisk taget fra sæt af statistiske datapunkter eller lister over numeriske værdier. For at finde en tilstand skal du derfor finde et datasæt for at finde det. Det er svært at lave modeberegninger mentalt for alle, men det mindste datasæt, så i de fleste tilfælde er det klogt at begynde at skrive (eller skrive) dine data. Hvis du arbejder med papir og blyant, er det bare at skrive værdierne af dit datasæt i rækkefølge, mens du, hvis du bruger en computer, kan bruge et regnearksprogram til at strømline processen.  2 Bestil tallene fra mindste til største. Derefter er det ofte en klog ide at sortere værdierne i dit datasæt, så de er i stigende rækkefølge. Selv om dette ikke er strengt nødvendigt, gør det processen at finde tilstanden lettere, fordi den grupperer ens værdier ved siden af hinanden. For store datasæt kan det være praktisk taget en nødvendighed, idet man sorterer gennem lange lister over værdier og holder mentale tal om hvor mange gange hvert nummer vises i listen, er svært og kan føre til fejl.
2 Bestil tallene fra mindste til største. Derefter er det ofte en klog ide at sortere værdierne i dit datasæt, så de er i stigende rækkefølge. Selv om dette ikke er strengt nødvendigt, gør det processen at finde tilstanden lettere, fordi den grupperer ens værdier ved siden af hinanden. For store datasæt kan det være praktisk taget en nødvendighed, idet man sorterer gennem lange lister over værdier og holder mentale tal om hvor mange gange hvert nummer vises i listen, er svært og kan føre til fejl.  3 Tæl antallet af gange hvert nummer gentages. Herefter tælle antal gange, som hvert nummer i sættet vises. Se efter den værdi, der forekommer mest i datasættet. For relativt små datasæt med punkter arrangeret i stigende rækkefølge er det normalt et simpelt spørgsmål om at finde den største "klynge" af identiske værdier og tælle antallet af forekomster.
3 Tæl antallet af gange hvert nummer gentages. Herefter tælle antal gange, som hvert nummer i sættet vises. Se efter den værdi, der forekommer mest i datasættet. For relativt små datasæt med punkter arrangeret i stigende rækkefølge er det normalt et simpelt spørgsmål om at finde den største "klynge" af identiske værdier og tælle antallet af forekomster.  4 Identificer den værdi (eller værdier), der forekommer oftest. Når du ved, hvor mange gange hver værdi opstår i dit datasæt, skal du finde den værdi, der forekommer det største antal gange. Dette er dit datasætets tilstand. Noter det der kan være mere end en tilstand i et datasæt. Hvis de to værdier er bundet til at være de mest almindelige værdier i sættet, kan datasættet siges at være bimodal, mens der er bundet tre værdier, er sættet trimodalt, og så videre.
4 Identificer den værdi (eller værdier), der forekommer oftest. Når du ved, hvor mange gange hver værdi opstår i dit datasæt, skal du finde den værdi, der forekommer det største antal gange. Dette er dit datasætets tilstand. Noter det der kan være mere end en tilstand i et datasæt. Hvis de to værdier er bundet til at være de mest almindelige værdier i sættet, kan datasættet siges at være bimodal, mens der er bundet tre værdier, er sættet trimodalt, og så videre.  5 Forveksl ikke datasættets tilstand med dets middel eller median. Tre statistiske begreber, der ofte diskuteres sammen, er midler, medianer og tilstande. Fordi disse begreber alle har lignende lydende navne, og fordi for en enkelt datasæt, kan en enkelt værdi undertiden være mere end en af disse ting er det let at forvirre dem. Men uanset om datasættets tilstand er også det er median eller middel, er det vigtigt at forstå, at disse tre begreber er helt uafhængige af hinanden. Se nedenunder:
5 Forveksl ikke datasættets tilstand med dets middel eller median. Tre statistiske begreber, der ofte diskuteres sammen, er midler, medianer og tilstande. Fordi disse begreber alle har lignende lydende navne, og fordi for en enkelt datasæt, kan en enkelt værdi undertiden være mere end en af disse ting er det let at forvirre dem. Men uanset om datasættets tilstand er også det er median eller middel, er det vigtigt at forstå, at disse tre begreber er helt uafhængige af hinanden. Se nedenunder: 

Metode To af to:
Finde tilstanden i særlige tilfælde
-
 1 Anerkend at der ikke findes nogen tilstand til datasæt, hvor hver værdi forekommer det samme antal gange. Hvis værdierne i et givet sæt alle forekommer det samme antal gange, har datasættet ingen tilstand, da der ikke er noget nummer mere end nogen anden. For eksempel, datasæt, hvor hver værdi forekommer en gang, har ingen tilstand. Det samme gælder for datasæt, hvor hver værdi forekommer to gange, tre gange og så videre.
1 Anerkend at der ikke findes nogen tilstand til datasæt, hvor hver værdi forekommer det samme antal gange. Hvis værdierne i et givet sæt alle forekommer det samme antal gange, har datasættet ingen tilstand, da der ikke er noget nummer mere end nogen anden. For eksempel, datasæt, hvor hver værdi forekommer en gang, har ingen tilstand. Det samme gælder for datasæt, hvor hver værdi forekommer to gange, tre gange og så videre. - Hvis vi ændrer vores eksempeldatasæt til 11, 15, 17, 18, 19, 21, så hver værdi kun forekommer en gang, har datasættet nu ingen tilstand. Det samme gælder, hvis vi ændrer datasættet, så hver værdi indtræffer to gange: 11, 11, 15, 15, 17, 17, 18, 18, 19, 19, 21, 21.
-
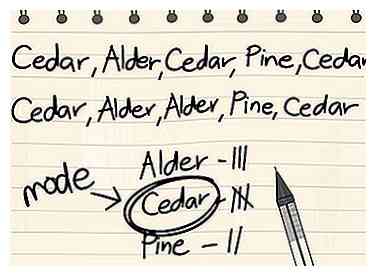 2 Anerkend at tilstande til ikke-numeriske datasæt kan findes på samme måde som for numeriske datasæt. Generelt er de fleste datasæt kvantitativ - de beskæftiger sig med data i form af tal Men nogle datasæt omhandler data, der ikke udtrykkes i form af tal. I disse tilfælde kan "mode" siges at være den enkeltværdi, der forekommer mest i datasættet, meget som det er for numeriske datasæt.[1] I disse tilfælde kan det være muligt at finde mode, mens det er umuligt at finde en meningsfuld median eller middel til datasættet.
2 Anerkend at tilstande til ikke-numeriske datasæt kan findes på samme måde som for numeriske datasæt. Generelt er de fleste datasæt kvantitativ - de beskæftiger sig med data i form af tal Men nogle datasæt omhandler data, der ikke udtrykkes i form af tal. I disse tilfælde kan "mode" siges at være den enkeltværdi, der forekommer mest i datasættet, meget som det er for numeriske datasæt.[1] I disse tilfælde kan det være muligt at finde mode, mens det er umuligt at finde en meningsfuld median eller middel til datasættet. - Lad os f.eks. Sige, at en biologisk undersøgelse bestemmer arten af hvert træ i en lille lokal del. Datasættet for trætypene i parken er Cedar, Alder, Cedar, Pine, Cedar, Cedar, Alder, Alder, Pine, Cedar. Denne type datasæt kaldes a nominel datasæt, fordi datapunkterne kun adskilles af deres navne. I dette tilfælde er datasættets tilstand Ceder fordi det forekommer oftest (fem gange i modsætning til tre for Alder og to for Pine).
- Bemærk, at det for det ovenstående eksempeldata er umuligt at beregne en middel eller median, fordi datapunkterne ikke har nogen numerisk værdi.
-
 3 Anerkend det for unimodale symmetriske udbredelser, mode, middel og median falder sammen. Som nævnt ovenfor er det muligt for mode, median og / eller at overlappe i visse tilfælde. I særlige tilfælde skal du vælge tilfælde, hvor datasætets tæthedsfunktion danner en perfekt symmetrisk kurve med en tilstand (for eksempel den gaussiske eller "bølgeformede" kurve), tilstanden, middelværdien og medianen vil alle have samme værdi. Fordi en fordelingsfunktion graver den relative forekomst af datapunkter, vil tilstanden naturligvis være i den nøjagtige midten af en symmetrisk fordelingskurve, da dette er det højeste punkt på grafen og svarer til den mest almindelige værdi. Da datasættet er symmetrisk, svarer dette punkt på grafen til medianen - middelværdien i datasættet - og middelværdien - gennemsnittet af datasættet.
3 Anerkend det for unimodale symmetriske udbredelser, mode, middel og median falder sammen. Som nævnt ovenfor er det muligt for mode, median og / eller at overlappe i visse tilfælde. I særlige tilfælde skal du vælge tilfælde, hvor datasætets tæthedsfunktion danner en perfekt symmetrisk kurve med en tilstand (for eksempel den gaussiske eller "bølgeformede" kurve), tilstanden, middelværdien og medianen vil alle have samme værdi. Fordi en fordelingsfunktion graver den relative forekomst af datapunkter, vil tilstanden naturligvis være i den nøjagtige midten af en symmetrisk fordelingskurve, da dette er det højeste punkt på grafen og svarer til den mest almindelige værdi. Da datasættet er symmetrisk, svarer dette punkt på grafen til medianen - middelværdien i datasættet - og middelværdien - gennemsnittet af datasættet. - Lad os f.eks. Overveje datasættet 1, 2, 2, 3, 3, 3, 4, 4, 5. Hvis vi skulle gradere fordelingen af dette datasæt, ville vi få en symmetrisk kurve, der når en højde på 3 ved x = 3 og aftager til en højde på 1 ved x = 1 og x = 5. Fordi 3 er mest almindelige værdi, det er tilstanden. Fordi det centrale 3 i datasættet har 4 værdier på hver side af det, er 3 også medianen. Endelig går gennemsnittet af datasættet ud til 1 + 2 + 2 + 3 + 3 + 3 + 4 + 4 + 5 = 27/9 = 3, hvilket betyder at 3 er også middelværdien.
- Undtagelsen fra denne regel er for symmetriske datasæt med mere end en tilstand - i dette tilfælde, fordi der kun kan være en median og middelværdi for datasættet, vil begge tilstande ikke falde sammen med disse andre punkter.
 1 Anerkend at der ikke findes nogen tilstand til datasæt, hvor hver værdi forekommer det samme antal gange. Hvis værdierne i et givet sæt alle forekommer det samme antal gange, har datasættet ingen tilstand, da der ikke er noget nummer mere end nogen anden. For eksempel, datasæt, hvor hver værdi forekommer en gang, har ingen tilstand. Det samme gælder for datasæt, hvor hver værdi forekommer to gange, tre gange og så videre.
1 Anerkend at der ikke findes nogen tilstand til datasæt, hvor hver værdi forekommer det samme antal gange. Hvis værdierne i et givet sæt alle forekommer det samme antal gange, har datasættet ingen tilstand, da der ikke er noget nummer mere end nogen anden. For eksempel, datasæt, hvor hver værdi forekommer en gang, har ingen tilstand. Det samme gælder for datasæt, hvor hver værdi forekommer to gange, tre gange og så videre.  2 Anerkend at tilstande til ikke-numeriske datasæt kan findes på samme måde som for numeriske datasæt. Generelt er de fleste datasæt kvantitativ - de beskæftiger sig med data i form af tal Men nogle datasæt omhandler data, der ikke udtrykkes i form af tal. I disse tilfælde kan "mode" siges at være den enkeltværdi, der forekommer mest i datasættet, meget som det er for numeriske datasæt.[1] I disse tilfælde kan det være muligt at finde mode, mens det er umuligt at finde en meningsfuld median eller middel til datasættet.
2 Anerkend at tilstande til ikke-numeriske datasæt kan findes på samme måde som for numeriske datasæt. Generelt er de fleste datasæt kvantitativ - de beskæftiger sig med data i form af tal Men nogle datasæt omhandler data, der ikke udtrykkes i form af tal. I disse tilfælde kan "mode" siges at være den enkeltværdi, der forekommer mest i datasættet, meget som det er for numeriske datasæt.[1] I disse tilfælde kan det være muligt at finde mode, mens det er umuligt at finde en meningsfuld median eller middel til datasættet.  3 Anerkend det for unimodale symmetriske udbredelser, mode, middel og median falder sammen. Som nævnt ovenfor er det muligt for mode, median og / eller at overlappe i visse tilfælde. I særlige tilfælde skal du vælge tilfælde, hvor datasætets tæthedsfunktion danner en perfekt symmetrisk kurve med en tilstand (for eksempel den gaussiske eller "bølgeformede" kurve), tilstanden, middelværdien og medianen vil alle have samme værdi. Fordi en fordelingsfunktion graver den relative forekomst af datapunkter, vil tilstanden naturligvis være i den nøjagtige midten af en symmetrisk fordelingskurve, da dette er det højeste punkt på grafen og svarer til den mest almindelige værdi. Da datasættet er symmetrisk, svarer dette punkt på grafen til medianen - middelværdien i datasættet - og middelværdien - gennemsnittet af datasættet.
3 Anerkend det for unimodale symmetriske udbredelser, mode, middel og median falder sammen. Som nævnt ovenfor er det muligt for mode, median og / eller at overlappe i visse tilfælde. I særlige tilfælde skal du vælge tilfælde, hvor datasætets tæthedsfunktion danner en perfekt symmetrisk kurve med en tilstand (for eksempel den gaussiske eller "bølgeformede" kurve), tilstanden, middelværdien og medianen vil alle have samme værdi. Fordi en fordelingsfunktion graver den relative forekomst af datapunkter, vil tilstanden naturligvis være i den nøjagtige midten af en symmetrisk fordelingskurve, da dette er det højeste punkt på grafen og svarer til den mest almindelige værdi. Da datasættet er symmetrisk, svarer dette punkt på grafen til medianen - middelværdien i datasættet - og middelværdien - gennemsnittet af datasættet. Facebook
Twitter
Google+